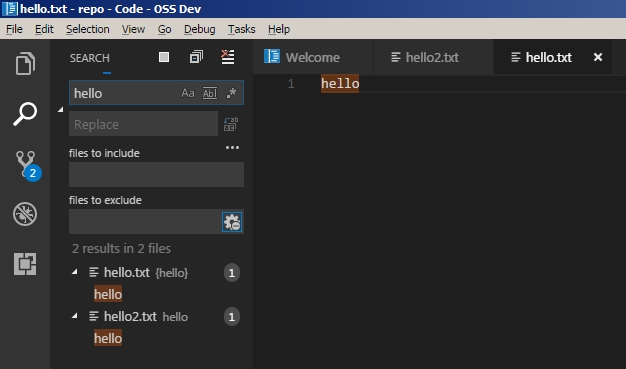
On my latest lab for open source development, I was tasked to fix an error in the Brave laptop/desktop web browser involving parsing of URL from the address bar. To fix this bug, I had to build the browser based on the source code from GitHub. Afterwards, I input several url test cases into the address bar and observe the behaviour from the Brave browser. Finally, I repeat the test cases on the Firefox and Chrome browsers to see if there were any differences in how the url is handled.
From the lab, there were many test cases offered, but ones that were of concern are as follows:
https://www.google.ca/search?q=dog cat/home/omak/Documents/dog cat.txt
For these test cases, the Brave browser will not treat the url as valid, and run a google search based on the url text. For the screenshots below, I used the url: https://www.google.ca/search?q=dog cat and tested the browser responses for Brave and Firefox. In Brave, the browser would perform a google search with the url input as keyword. This is in contrast to Firefox, where the browser would parse the url and decipher the search terms to only be “dog cat”.
To get the class started on fixing the bug, our professor introduced us to the code involved in Url parsing for Brave and Firefox. For Firefox, it was based on C++ code that went as far as the Netscape days, whereas for Brave, it was Javascript code.
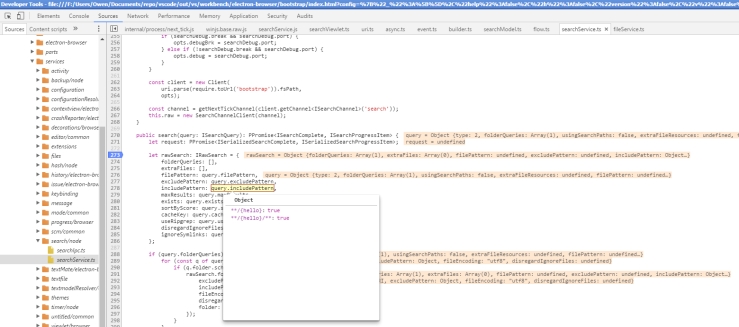
Since this was a test driven development style of programming, I was supposed to write a set of test cases prior to changing the code in urlutil.js. The first function I studied closely was the getUrlFromInput() function, because I felt that if I could change the way the string is retrieved from the address bar, I can control what is passed to the subsequent function calls. To begin, I wrote a new test case for the getUrlFromInput as per the gist below:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| describe('getUrlFromInput', function () { | |
| it('returns empty string when input is null', function () { | |
| assert.equal(urlUtil.getUrlFromInput(null), '') | |
| }) | |
| it('returns empty string when input is undefined', function () { | |
| assert.equal(urlUtil.getUrlFromInput(), '') | |
| }) | |
| it('calls prependScheme', function () { | |
| assert.equal(urlUtil.getUrlFromInput('/file/path/to/file'), 'file:///file/path/to/file') | |
| }) | |
| it('calls prependScheme with space in file name', function () { | |
| assert.equal(urlUtil.getUrlFromInput('/home/omak/Documents/dog cat.txt'), 'file:///home/omak/Documents/dog%20cat.txt') | |
| }) | |
| }) |
Strangely, when I ran the new test case with the expectation of failure, the following happened:
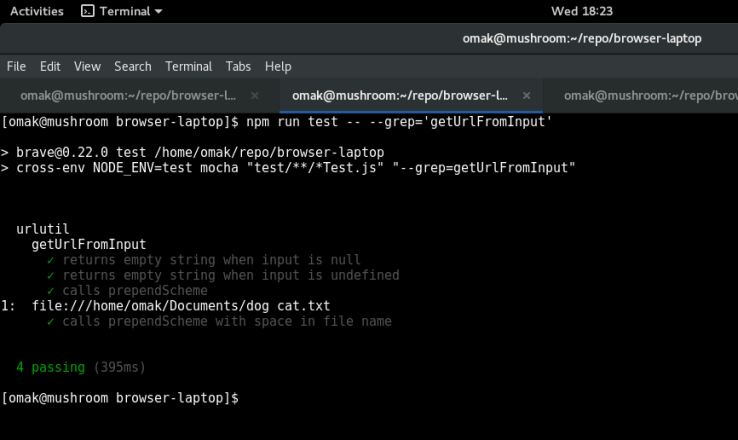
Since this test case passed, my professor indicated to me that it meant getUrlFromInput() is not the function causing the erroneous behaviour.
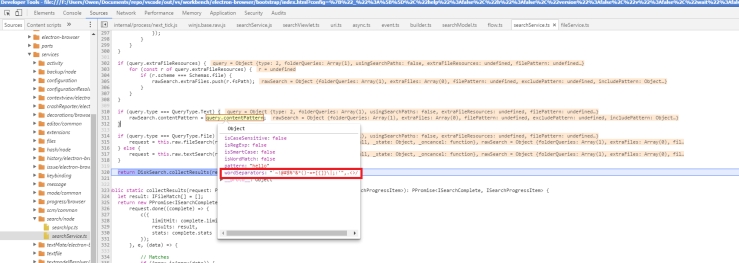
I moved on to looking at another function in the urlutil.js of particular interest. This time, it was the isNotURL() function. By manipulating the inputs that get flagged as a valid urls, I can control the strings that processed as a Url and the strings that are processed as keyword searches. To start things off again, I wrote two test cases for the isNotURL() function, located at the bottom of the test cases:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| describe('isNotURL', function () { | |
| describe('returns false when input:', function () { | |
| it('is a valid URL', function () { | |
| assert.equal(urlUtil.isNotURL('brave.com'), false) | |
| }) | |
| it('is an absolute file path without scheme', function () { | |
| assert.equal(urlUtil.isNotURL('/file/path/to/file'), false) | |
| }) | |
| it('is an absolute file path with scheme', function () { | |
| assert.equal(urlUtil.isNotURL('file:///file/path/to/file'), false) | |
| }) | |
| describe('for special pages', function () { | |
| it('is a data URI', function () { | |
| assert.equal(urlUtil.isNotURL('data:text/html,hi'), false) | |
| }) | |
| it('is a view source URL', function () { | |
| assert.equal(urlUtil.isNotURL('view-source://url-here'), false) | |
| }) | |
| it('is a mailto link', function () { | |
| assert.equal(urlUtil.isNotURL('mailto:brian@brave.com'), false) | |
| }) | |
| it('is an about page', function () { | |
| assert.equal(urlUtil.isNotURL('about:preferences'), false) | |
| }) | |
| it('is a chrome-extension page', function () { | |
| assert.equal(urlUtil.isNotURL('chrome-extension://fmfcbgogabcbclcofgocippekhfcmgfj/cast_sender.js'), false) | |
| }) | |
| it('is a magnet URL', function () { | |
| assert.equal(urlUtil.isNotURL('chrome://gpu'), false) | |
| }) | |
| it('is a chrome page', function () { | |
| assert.equal(urlUtil.isNotURL('magnet:?xt=urn:sha1:YNCKHTQCWBTRNJIV4WNAE52SJUQCZO5C'), false) | |
| }) | |
| }) | |
| it('contains a hostname and port number', function () { | |
| assert.equal(urlUtil.isNotURL('someBraveServer:8089'), false) | |
| }) | |
| it('starts or ends with whitespace', function () { | |
| assert.equal(urlUtil.isNotURL(' http://brave.com '), false) | |
| assert.equal(urlUtil.isNotURL('\n\nhttp://brave.com\n\n'), false) | |
| assert.equal(urlUtil.isNotURL('\t\thttp://brave.com\t\t'), false) | |
| }) | |
| it('is a URL which contains basic auth user/pass', function () { | |
| assert.equal(urlUtil.isNotURL('http://username:password@example.com'), false) | |
| }) | |
| it('is localhost (case-insensitive)', function () { | |
| assert.equal(urlUtil.isNotURL('LoCaLhOsT'), false) | |
| }) | |
| it('is a hostname (not a domain)', function () { | |
| assert.equal(urlUtil.isNotURL('http://computer001/phpMyAdmin'), false) | |
| }) | |
| it('ends with period (input contains a forward slash and domain)', function () { | |
| assert.equal(urlUtil.isNotURL('brave.com/test/cc?_ri_=3vv-8-e.'), false) | |
| }) | |
| it('is a string with whitespace but has schema', function () { | |
| assert.equal(urlUtil.isNotURL('https://wwww.brave.com/test space.jpg'), false) | |
| }) | |
| it('has custom protocol', function () { | |
| assert.equal(urlUtil.isNotURL('brave://test'), false) | |
| }) | |
| it('is a url which contains a space in the query', function () { | |
| assert.equal(urlUtil.isNotURL('https://www.google.ca/search?q=dog cat'), false) | |
| }) | |
| it('is an absolute file path with a space in the files', function () { | |
| assert.equal(urlUtil.isNotURL('/home/omak/Documents/dog cat.txt'), false) | |
| }) | |
| }) |
The test cases failed as expected, and I knew from this failure that I had to modify some of the code in the isNotUrl() function.
To fix the behaviour in Brave, I had to work with 3 cases. The first case is to check if there was a scheme to the url, and then look for a space in the url text. If there is a scheme, then the url is definitely not a file path, and what I needed to do was to replace the whitespace ONLY in the query section of the url string with ‘%20’. At first, I simply replaced all whitespace in the entire url string and triggered a new error in one of the existing test case:
assert.equal(urlUtil.isNotURL('https://www.bra ve.com/test space.jpg'), true)
My fix would mistakenly trigger an error on this case because it would replace the whitespace in ‘bra ve’ and change it to ‘bra%20’. Afterwards, the browser would attempt to go to url https://www.bra%20ve.com/test space.jpg and result in an error.
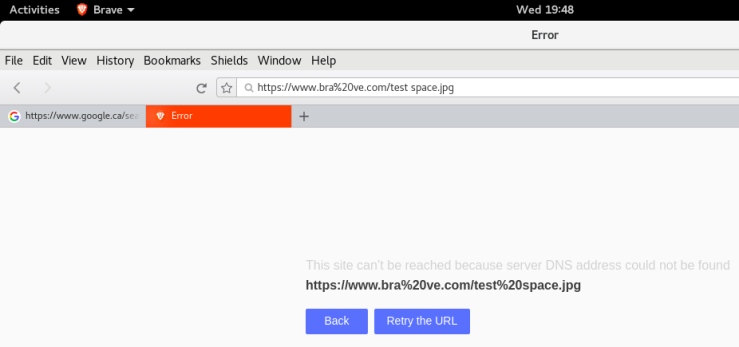
To prevent this error, I had to check the case of an existing scheme (http or https), and then check for a space in the url string. Afterwards, I would search for a ‘?’, such that I will only replace the whitespace in the query part of the url. Here’s a short snippet of the code I used to perform this replacement:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| if (/\s/g.test(str) && scheme !== undefined) { | |
| // attempt to change query whitespace to %20 | |
| var queryIndex = str.search(/\?.*$/) | |
| if (queryIndex > 0) { | |
| var query = str.substring(queryIndex).replace(/\s/g, '%20') | |
| str = str.substring(0, queryIndex) + query | |
| } | |
| } |
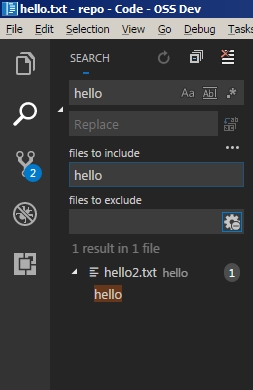
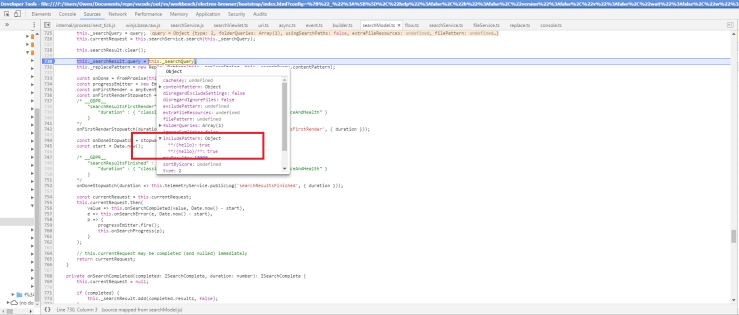
After the small addition, passing an url such as https://www.google.ca/search?q=dog cat hamster would replace only the spaces in the query string, and leave string in domain name unchanged. The following slides demonstrates this behaviour.
The last two cases of ‘dog cat’ and ‘/home/omak/Documents/dog cat.txt’ would be fixed under the same section of the isNotUrl() function.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| if (case2Reg.test(str) || !case3Reg.test(str) || | |
| (scheme === undefined && /\s/g.test(str))) { | |
| if (scheme === undefined && /\s/g.test(str)) { | |
| // check to see if undefined scheme is possibly file scheme | |
| let str1 = UrlUtil.prependScheme(str) | |
| if (UrlUtil.isFileScheme(str1)) { | |
| // if it is file scheme, will then replace whitespace with %20 | |
| str = str.replace(' ', '%20') | |
| } else { | |
| return true | |
| } | |
| } else { | |
| return true | |
| } | |
| } |
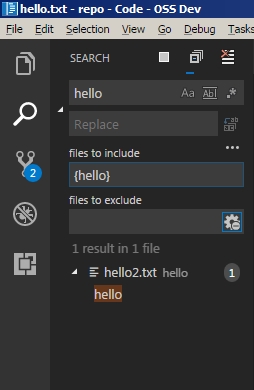
This code will only replace the whitespace if the url is a file path. This means only file paths such as ‘/home/omak/Documents/dog cat.txt’ will be converted to ‘/home/omak/Documents/dog%20cat.txt. Strings such as ‘dog cat’ will remain as google searches and left untouched.
With the two fixes, I managed to get Brave to work for the following urls:
https://www.google.ca/search?q=dog catdog cat/home/omak/Documents/dog cat.txthttps://www.bra ve.com/test space.jpg
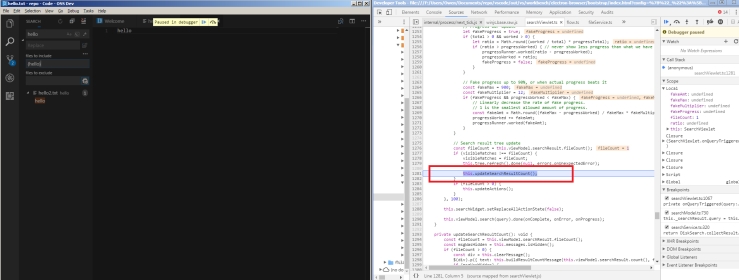
This is a final screenshot to show my test cases are working at the end.
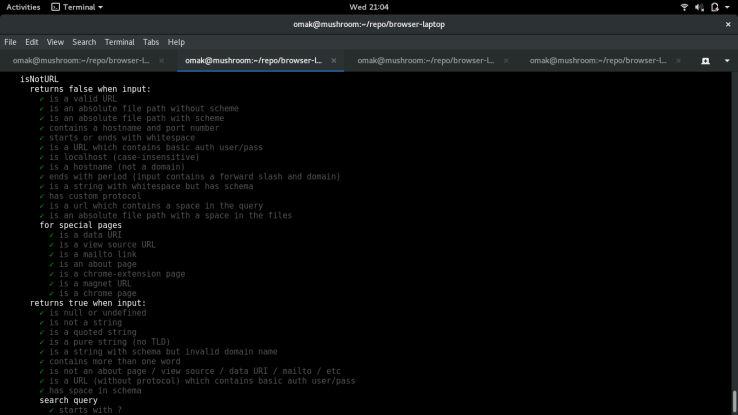
The commit to this fix is located here.
Learning experience:
From this exercise, the biggest learning experience was from comparing the way firefox wrote their code in C++ to the way it was written in Javascript for Brave. By comparing the two codebase, one could tell a lot has changed in software development from the days of Netscape to current coding practices. In particular, in the Firefox code base, the naming of variables based on facts about the variable, such as it being a member variable, therefore they put a ‘m’ before the variable name was quite interesting for me. Another interesting note was the canParseURL() function in the urlutil.js, where the professor explained the case of window being undefined, highlighting the possibility of the function not being used from a browser.
This exercise was also my first time trying Test Driven Development, and it was quite different for me to write out my test cases first, and then modify the code base. As mentioned above, I was quite surprised to have my test case on getUrlFromInput() pass, when it should have failed. This scenario demonstrated the merits of writing out the test case first, as I would have wasted a lot of time fiddling with the getUrlFromInput() method otherwise.